Attractivechaos's stuff blows my mind. Shameless plug - I've started dissecting his header-only hashmap library (khash.h) bit by bit, and I've been documenting my adventure here:
No clue! Your comment history seems to say you're more qualified to answer that than me.
My first look says that dense_hash_map seems to use STL stuff and generics, khash is in pure C, and uses macro hacks to achieve the same functionality and only has a few key types it can use (str, int, int64).
Other than that, dense_hash_map and khash both use quadratic probing (https://en.wikipedia.org/wiki/Quadratic_probing) to resolve collisions. I couldn't really dig and find the hashing functions used by dense_hash_map but khash uses a weird one called X31 (search in https://download.samba.org/pub/unpacked/ntdb/lib/ccan/hash/h...) for the string ones and .... nothing??? for ints, with an alternative of Wang's integer hash function (https://gist.github.com/badboy/6267743). The world of hashing functions seem to be a crazy underworld of arcane incantations, old tomes, and copy pasting and emailing and trying random shit. It's really wonderful, reminds me of the olden days.
Khash.h is a measly 624 lines of code, everything included, so there's that.
Good write up. It is very rare to outperform decades of numeric analysts (and also avoid nasty machine precision issues) by shooting from the hip, and Eigen is amazingly easy to use (plus it is a headers-only implementation: no DLL).
MKL is a BLAS substitute (with some additional features like the Vector Statistical Library). Eigen is a higher level library that can call BLAS functions. For what it's worth, OpenBLAS is now on-par with MKL on most benchmarks.
Eigen can use MKL as a backend, but not by default. I don't have MKL installed on my machine (don't have a license on that linux server), so Eigen is entirely using its own matrix multiplication code.
Any programmer with a competent faculty for science can see that your experiment is flawed:
1. too many indepedent variables: comparing two different compilers on two different platforms on two different architectures?!!
2. and then you compare performances without equal consideration of the problem size for n!
your conclusions are premature, sir, your analysis is conjecture and yet you dare use the word "primitive". for instance, are you aware that Blas uses Fortran whose lack of pointer aliasing effects in memory could be causing the disparity here? have you considered that certain interprocedural optimizations have been affected by not having seperate translation units for your tests?! you have also added debugging flags to the compilers further slowing the BLAS routines with more debugging cruft!?! gah!
for these reasons above and the flaunted use of architecture specific intrinsics, your post stands accused! make revisions and then also see how blas performs using a better algorithm with possibly fewer aliasing effects
> 2. and then you compare performances without equal consideration of the problem size for n!
All the different implementations are compared on the same condition: same n, same compiler and same machine.
> are you aware that Blas uses Fortran
Wrong. uBLAS and Eigen are written purely in C++. OpenBLAS is a mixture of C and ASM. They have nothing to do with Fortran.
> you have also added debugging flags to the compilers further slowing the BLAS routines with more debugging cruft!?
By debugging flags, you mean "-g"? No, -g should not affect the performance (maybe a tiny bit on loading the executable, but that is negligible). Get rid of -g, and you will get essentially the same result.
> you dare use the word "primitive"
Yes, I dare, because uBLAS is just that bad and should be trashed. Prove me wrong with your benchmarks. Let number speak for itself.
Some time ago I did compare different BLAS implementations (OpenBLAS, MKL, ACML etc) on different Intel CPU architectures, in case somebody is interested in the differences between them
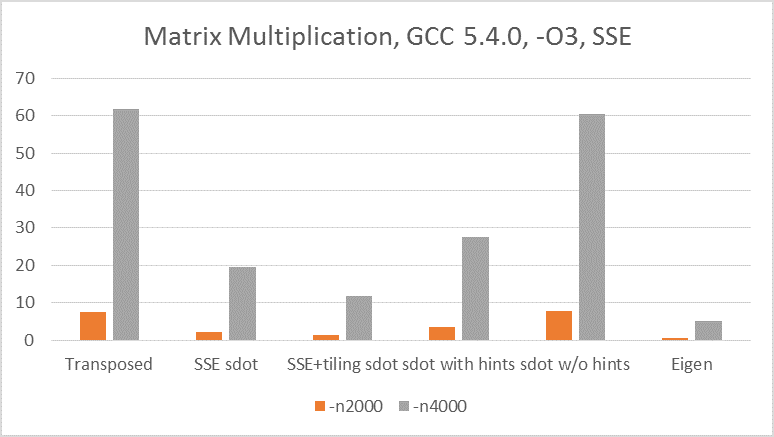
You have a faster CPU. "SSE sdot" and "SSE+tiling" are both faster on your machine. However, "Eigen" is slower. This suggests gpderetta might be right – MSVC is not as good as gcc to optimize Eigen, or conversely, Eigen has not been optimized for MSVC. Nonetheless, MSVC did fully vectorize the inner loop of non-SSE sdot, better than both gcc and clang (EDIT: of the versions I was using; it would be good to try the latest gcc/clang). It seems that explicit SSE vectorization is the most stable. Other implementations of "sdot" depend too much on the behavior of compilers.
Anyway, thanks a lot for this experiment. I rarely use MSVC these days. It is good to know where it stands.
Both CPUs are same microarch, Haswell. Xeon has much more cache. The i5 has higher base frequency (3.2 vs 2.6) the Xeon however has higher turbo frequency (3.6 vs 3.4).
OK, I’ve installed Cygwin and GCC, compiled and benchmarked the original code. I made the following changes in the makefile: (1) Replaced -O2 with -O3 (2) added -msse -msse2 -msse3 -mssse3 -msse4 -msse4.1 to the option, both C and C++.
The results on GCC/i5/Windows 10 are very consistent with the OPs result on GCC/Xeon/Linux.
> Apparently, the main reason for your results — GCC optimizer ain’t good.
while that could be the case, it does not follow from your results; you need to compare GCC and MSVC directly. It might rather be that MSVC is not capable to optimize Eigen enough to give it a larger advantage over SSE+tiling.
From experience MSVC is less capable of aggressive abstraction elimination (the bread and butter of Eigen) than GCC.
OK, did that. Results for GCC are very close to the OP’s results for Xeon.
GCC indeed did better optimization of Eigen than MSVC. Specifically, about 25% better. I think that might be because authors of Eigen have very intimate knowledge on GCC’s optimizer, and somehow specifically optimized their code for GCC compiler.
However, for the rest of the test cases, MSVC performed much better. For example, for Transposed algorithm, MSVC result is 3.5 times faster - huge difference.
Just wanted to share this video given at ANL recently which goes into the cost of communication in such methods. It has a HPC focus but the presentation is quite digestible.
I don't like how the author has labeled tables as "Linux" and "Mac", when really most of the differences between those columns are the result of the compiler used, and to a lesser extent, the fact that the Mac was a local machine while the "Linux" tests were done on a remote server.
A much more useful comparison would keep everything constant except the single variable that is different. This could have been done by utilizing the same hardware, and only using a different compiler. Since both GCC & Clang work on both linux & mac, there is no excuse.
I'd like to see support for optimized multiplication on symmetric matrices. I don't think BLAS can take advantage of that, certainly scipy/numpy doesn't.
There is BLAS level 2 (f|d)symv for matrix-vector multiplies and BLAS level 3 (f|d)symm for matrix-matrix multiplies. Last time I benchmarked symv, it was slower than the general implementation by around 25%...
Disclaimer: I have very, very, very little experience using BLAS. The reasons I post this are:
- the original poster gave an unqualified speed difference, which cannot reasonably be the full story. They likely left out information such as a 'for my use case' clause.
- I was curious, too, but couldn't Google benchmarks.
Having said that, my guess would be that it is slower for small matrices (where algorithm overhead plays a role), but faster for larger ones (where speed probably is proportional to memory access speed times amount of data accessed). There's a similarity here with searching a sorted array. There, a linear search is faster than a binary search up to a surprisingly large N.
I wouldn't dare guess where the cut-off point lies, but it likely lies at a point above where a matrix row fills a cache line (below that, reading only a few entries of a row brings in an entire row, anyways). For a level 1 cache line of 64 bytes, for floats, that would be a 16x16 matrix.
The transpose "trick" should work the same way and have similar beneficial cache effects. Manually unrolling the sdot loop should probably help, too. Vectorized intrinsics are also available from .NET, so that should work as well: https://msdn.microsoft.com/en-us/library/hh977022.aspx
{kind=link}
https://medium.com/@makmanalp/dissecting-khash-h-part-1-orig...
edit: and part 2:
https://medium.com/@makmanalp/dissecting-khash-h-part-2-scou...