I haven't actually used bpftrace myself, only BCC. I can totally imagine it being more janky than DTrace, BCC is pretty janky even if I also think it's cool. In my eBPF tracing framework I had to add special handling counters to alert you if it ever lost any events, plausible bpftrace didn't do that.
I think if you're working mostly with tracing/sampling specific applications you'll be more of a BCC person, while if you're hired to diagnose problems in a wide variety of applications then you might learn to like bpftrace more.
Do you know of anyone who's built that kind of time travel debugging with a trace visualization in the open outside of Javascript? I know about rr and Pernosco but don't know of trace visualization integration for either of them, that would indeed be very cool. I definitely dream of having systems like this.
At undo.io we're interested in using our time travel capability beyond conventional time travel debugging - a recording file contains everything the program did, without any advance knowledge of what you need to sample, so there's a lot of potential to get other data out of it.
I just read your post and don't think it would take much to integrate with some of the visualisations you posted about, as a first step.
But that's not quite the kind of tracing you're talking about. We also built a printf-style interface to our recording files, which seems closer:
https://docs.undo.io/PostFailureLogging.html
Something like that but outputting trace events that can be consumed by Perfetto (say) would not be so hard to add. If we considered modifying the core record/replay engine then even more powerful things become possible.
I've seen undo.io several times at cppcon. I've been throughly impressed with the demonstrations at the conference and came to this thread specifically to recommend undo.io. I was particularly impressed this year by a demonstration of debugging stack smashing -- that's something I recently worked around stack smashing in protobuf which happens before `main()` even starts. It seems perfect for undo.io to help debug :)
I'm still waiting on the keyserver to be able to run in Kubernetes though
No particularly good publicly visible documentation of the functionality, but it does that and is a publicly purchasable product.
They also had TimeMachine + PathAnalyzer from the early 2000s which was a time travel debug with visualization solution, but they were only about as integrated as most of the solutions you see floating around today.
To me most interesting are factors I didn't consider in features I did cover. Next most interesting are features I didn't cover which are kinda core to Twitter being good, and also pose interesting performance problems, like the person who mentioned spam/abuse detection. After that are non-core features which pose interesting performance problems that are different from problems I already covered.
The comments that I think aren't contributing much are ones that mention features that I didn't cover but make no attempt to argue that they're actually hard to implement efficiently, or that assert that because I didn't implement something it isn't feasible to make as fast as I calculate, without arguing what would actually stop me from implementing something that efficient. Or ones who repeat that this isn't practical, which I say at length in the post.
Which I think I'm perfectly clear about in the blog post. The post is mostly about napkin math systems analysis, which does cover HTTP and HTTPS.
I'm now somewhat confident I could implement this if I tried, but it would take many years, the prototype and math is to check whether there's anything that would stop me if I tried and be a fun blog post about what systems are capable of.
I've worked on a team building a system to handle millions of messages per second per machine, and spending weeks doing math and building performance prototypes like this is exactly what we did before we built it for real.
I agree most HTTP server benchmarks are highly misleading in that way, and mention in my post how disappointed I am at the lack of good benchmarks. I also agree that typical HTTP servers would fall over at much lower new connection loads.
I'm talking about a hypothetical HTTPS server that used optimized kernel-bypass networking. Here's a kernel-bypass HTTP server benchmarked doing 50k new connections per core second while re-using nginx code: https://github.com/F-Stack/f-stack. But I don't know of anyone who's done something similar with HTTPS support.
I once built a quick and dirty load testing tool for a public facing service we built. The tool was pretty simple - something like https://github.com/bojand/ghz but with traffic and data patterns closer to what we expected to see in the real world. We used argo-workflows to generate scale.
One thing which we noticed was that there was a considerable difference in performance characteristics based on how we parallelized the load testing tool (multiple threads, multiple processes, multiple kubernetes pods, pods forced to be distributed across nodes).
I think that when you run non-distrubuted load tests you benefit from bunch of cool things which happen with http2 and Linux (multiplexing, resource sharing etc) which might make applications seem much faster than they would be in the real world.
TLS handling would dominate your performance, kernel bypassing would not help here unless you would also do TLS NIC offloading, you still need to process new TLS sessions from OP example and they would dominate your http processing time (excluding application business logic processing).
"Quant uses the warpcore zero-copy userspace UDP/IP stack, which in addition to running on on top of the standard Socket API has support for the netmap fast packet I/O framework, as well as the Particle and RIOT IoT stacks. Quant hence supports traditional POSIX platforms (Linux, MacOS, FreeBSD, etc.) as well as embedded systems."
Quote tweets I'd do as a reference and they'd basically have the cost of loading 2 tweets instead of one, so increasing the delivery rate by the fraction of tweets that are quote tweets.
Hashtags are a search feature and basically need the same posting lists as for search, but if you only support hashtags the posting lists are smaller. I already have an estimate saying probably search wouldn't fit. But I think hashtag-only search might fit, mainly because my impression is people doing hashtag searches are a small fraction of traffic nowadays so the main cost is disk, not sure though.
I did run the post by 5 ex-Twitter engineers and none of them said any of my estimates were super wrong, mainly just brought up additional features and things I didn't discuss (which I edited into the post before publishing). Still possible that they just didn't divulge or didn't know some number they knew that I estimated very wrong.
I think the difficult part would be that tagging and indexing the relationship between a single tweet and all of its component hashtags (which you would then likely want metrics on to avoid needing to count indexes on, etc.) is where it would really start to inflate.
Another poster dug into some implementation details that I'm not going to go into. I think you could shoehorn it into an extremely large server alongside the rest of your project but then you're looking at processing overhead and capacity management around the indexes themselves starting to become a more substantial part of processing power. Consider that for each tweet you need to break out what hashtags are in it, create records, update indexes, and many times there's several hashtags in a given tweet.
When I last ran analytics on the firehose data (ca. 2015/16) I saw something like 20% of all tweets had 3 or more hashtags. I only remember this fact because I built a demo around doing that kind of analytics. That may have changed over time obviously, however without that kind of information we don't have a good guesstimate even of what storage and index management there looks like. I'd be curious if the former Twitter engineers you polled worked on the data storage side of things. Coming at it from the other end of things, I've met more than a few application engineers who genuinely have no clue how much work a DBA (or equivalent) does to get things stored and indexed well and responsively.
This is critically wrong, and misses the point of the cliché entirely.
Absence of evidence, in your case via a clean building inspection, does not mean the building is safe. It just means the checklist of known items was considered and nothing bad found.
Ask a building inspector if their clean report proves nothing is wrong with the building.
They will be firm and quick to inform you that it’s not a warranty — anything not checked was not covered. Items not covered could still be significant problems.
That’s the whole point of the saying. Absence of evidence is not evidence of absence.
Sure, but if someone accuses your house of having issues, and you retort that you've had it inspected by professionals, a reply of "Hah! That's evidence, not proof!" is just a bit smarmy.
A few weeks ago there was in incident[0] in Jersey, where some people called fire fighters one evening because they could smell gas, the fire fighters didn’t find any leaks, and the building literally blew up the next morning. Experts make mistakes, and failing to understand that evidence != proof can literally kill people. Sometimes, making the distinction is smarmy; other times, it’s just being sensible.
Okay, but... we're spit balling database sizes. None of this is safety critical, or even in the general neighborhood of things where it's important enough to go and mathematically prove that our numbers are perfect.
I don’t think that hashtags are a search only feature. In the posts themselves, the hashtags are clickable to view other tweets. I don’t think that qualifies as a search.
It does strike me as a feature you'd typically serve out of some sort of search index since if you had to build search, you'd essentially get indexing of hashtags "for free"
You are probably right and I am wrong. I just looked at a tweet and clicking the hashtag takes to the search page with that hashtag typed in. Probably implemented similarly behind the scenes. Though hashtag most likely does an exact match search instead of fuzzy searching for regular words and phrases.
My friend mentioned this just before I published and I think that probably is the fastest largest thing you can get which would in some sense count as one machine. I haven't looked into it, but I wouldn't be surprised if they could get around the trickiest constraint, which is how many hard drives you can plug in to a non-mainframe machine for historical image storage. Definitely more expensive than just networking a few standard machines though.
I also bet that mainframes have software solutions to a lot of the multi-tenancy and fault tolerance challenges with running systems on one machine that I mention.
> which is how many hard drives you can plug in to a non-mainframe machine for historical image storage.
You would be surprised. First off, SSDs are denser than hard drives now if you're willing to spend $$$.
Second, "plug in" doesn't necessarily mean "in the chassis". You can expand storage with external disk arrays in all sorts of ways. Everything from external PCI-e cages to SAS disk arrays, fibre channel, NVMe-over-Ethernet, etc...
It's fairly easy to get several petabytes of fast storage directly managed by one box. The only limit is the total usable PCIe bandwidth of the CPUs, which for a current-gen EPYC 9004 series processors in a dual-socket configuration is something crazy like 512 GB/s. This vastly exceeds typical NIC speeds. You'd have to balance available bandwidth between multiple 400 Gbps NICs and disks to be able to saturate the system.
People really overestimate the data volume put out by a service like Twitter while simultaneously underestimating the bandwidth capability of a single server.
> People really overestimate the data volume put out by a service like Twitter while simultaneously underestimating the bandwidth capability of a single server.
It's outright comical. Above we have people thinking somehow amount of TLS connections single server can handle is a problem, in service where there would be hundreds of thousands lines of code to generate the content served over it, all while using numbers from what seems like 10+ years old server hardware
That's really cool! Each year of historical images I estimate at 2.8PB, so it would need to scale quite far to handle multiple years. How would you actually connect all those external drive chassis, is there some kind of chainable SAS or PCIe that can scale arbitrarily far? I consider NVMe-over-fabrics to be cheating and just using multiple machines and calling it one machine, but "one machine" is kinda an arbitrary stunt metric.
It depends on how you think of "one machines". :) You can fit 1PB in 1U without something like NVMe-over-fabrics. So in a 4U unit gives you plenty of room.
We have Zen4c 128 Core with DDR5 now. We might get a 256 Core Zen6c with PCI-E 6.0 and DDR6 by 2026.
I really like these exercise of trying to shrink the amount of server needed, especially those on Web usage. And the mention of Mainframe. Which dont get enough credit for. I did something similar with Netflix 800Gbps's post. [1] Where they could serve every single user with less than 50 Racks by the end of this decade.
Stuff like [0] exists, allowing you to fan out a single server's PCIe to quite a few PCIe JBOD chassis. Considering that SSDs can get you ~1PB in 1U these days, you can get pretty far while still technically sticking with PCIe connectivity rather than NVMeoF.
Is an infiniband switch connected to a bunch of machines that expose NVMe targets really that different from a SAS expander connected to a bunch of JBOD enclosures? Only difference is that the former can scale beyond 256 drives per controller and fill an entire data center. You're still doing all the compute on one machine so I think it still counts.
It's a neat thought exercise, but wrong for so many reasons (there are probably like 100s). Some jump out: spam/abuse detection, ad relevance, open graph web previews, promoted tweets that don't appear in author timelines, blocks/mutes, etc. This program is what people think Twitter is, but there's a lot more to it.
I think every big internet service uses user-space networking where required, so that part isn't new.
I think I'm pretty careful to say that this is a simplified version of Twitter. Of the features you list:
- spam detection: I agree this is a reasonably core feature and a good point. I think you could fit something here but you'd have to architect your entire spam detection approach around being able to fit, which is a pretty tricky constraint and probably would make it perform worse than a less constrained solution. Similar to ML timelines.
- ad relevance: Not a core feature if your costs are low enough. But see the ML estimates for how much throughput A100s have at dot producting ML embeddings.
- web previews: I'd do this by making it the client's responsibility. You'd lose trustworthiness though so users with hacked clients could make troll web previews, they can already do that for a site they control, but not a general site.
- blocks/mutes: Not a concern for the main timeline other than when using ML, when looking at replies will need to fetch blocks/mutes and filter. Whether this costs too much depends on how frequently people look at replies.
I'm fully aware that real Twitter has bajillions of features that I don't investigate, and you couldn't fit all of them on one machine. Many of them make up such a small fraction of load that you could still fit them. Others do indeed pose challenges, but ones similar to features I'd already discussed.
"web previews: I'd do this by making it the client's responsibility."
Actually a good example of how difficult the problem is. A very common attack is to switch a bit.ly link or something like that to a malicious destination. You would also DoS the hosts... as the Mastodon folks are discovering (https://www.jwz.org/blog/2022/11/mastodon-stampede/)
For blocks/mutes, you have to account for retweets and quotes, it's just not a fun problem.
Shipping the product is much more difficult that what's in your post. It's not realistic at all, but it is fun to think about.
I do agree that some of this could be done better a decade later (like, using Rust for some things instead of Scala), but it was all considered. A single machine is a fun thing to think about, but not close to realistic. CPU time was not usually the concern in designing these systems.
I'll go ahead and quote that blog post because they block HN users using the referer header.
---
"Federation" now apparently means "DDoS yourself."
Every time I do a new blog post, within a second I have over a thousand simultaneous hits of that URL on my web server from unique IPs. Load goes over 100, and mariadb stops responding.
The server is basically unusable for 30 to 60 seconds until the stampede of Mastodons slows down.
Presumably each of those IPs is an instance, none of which share any caching infrastructure with each other, and this problem is going to scale with my number of followers (followers' instances).
This system is not a good system.
Update: Blocking the Mastodon user agent is a workaround for the DDoS. "(Mastodon|http\.rb)/". The side effect is that people on Mastodon who see links to my posts no longer get link previews, just the URL.
---
I personally find this absolutely hilarious. Is that blog hosted on a Raspberry Pi or something? "Over a thousand" requests per second shouldn't even show up on the utilization graphs on a modern server. The comments suggest that he's hitting the database for every request instead of caching GET responses, but even with such a weird config a normal machine should be able to do over 10k/second without breaking a sweat.
> I personally find this absolutely hilarious. Is that blog hosted on a Raspberry Pi or something? "Over a thousand" requests per second shouldn't even show up on the utilization graphs on a modern server.
Mastodon is written on Ruby on Rails. That should really answer all your questions about the problem but if you're unfamiliar Ruby is slow compared to any compiled language, Rails is slow compared to near-every framework on the planet and it isn't written that well either.
While that may be funny, the number of Mastodon instances is growing rapidly, to the point where it will need to eventually be dealt with (not least because hosting on a Pi or having a badly optimized setup both happens in real life). But more to this example, it shows passing preview responsibility to end user clients is a far bigger problem. Eg not many would be able to handle the onslaught of being linked to from a highly viral tweet if previews weren't cached.
> I haven't looked into it, but I wouldn't be surprised if they could get around the trickiest constraint, which is how many hard drives you can plug in to a non-mainframe machine for historical image storage.
Netapp is at something > 300TB storage per node IIRC, but in any case it would make more sense to use some cloud service. AWS EFS and S3 don't have any (practically reachable) limit in size.
Because both are ridiculously slow to the point where they would be completely unusable for a service such as Twitter whose current latency is based off everything largely being in memory.
And Twitter already evaluated using the cloud for their core services and it was cost-prohibitive compared to on-premise.
> I wouldn't be surprised if they could get around the trickiest constraint, which is how many hard drives you can plug in to a non-mainframe machine for historical image storage.
Some commodity machines use external SAS to connect to more disk boxes. IMHO, there's not a real reason to keep images and tweets on the same server if you're going to need an external disk box anyway. Rather than getting a 4u server with a lot of disks and a 4u additional disk box, you may as well get 4u servers with a lot of disks each, use one for tweets and the other for images. Anyway, images are fairly easy to scale horizontally, there's not much simplicity gained by having them all in one host, like there is for tweets.
Yah like I say in the post, the exactly one machine thing is just for fun and as an illustration of how far vertical scaling can go, practically I'd definitely scale storage with many sharded smaller storage servers.
Incidentally, a lot of people have argued that the massive datacenters used by e.g. AWS are effectively single large ("warehouse-scale") computers. In a way, it seems that the mainframe has been reinvented.
to me the line between machine and cluster is mostly about real-time and fate-sharing. multiple cores on a single machine can expect memory accesses to succeed, caches to be coherent, interrupts to trigger within a deadline, clocks not to skew, cores in a CPU not to drop out, etc.
in a cluster, communication isn't real-time. packets drop, fetches fail, clocks skew, machines reboot.
IPC is a gray area. the remote process might die, its threads might be preempted, etc. RTOSes make IPC work more like a single machine, while regular OSes make IPC more like a network call.
so to me, the datacenter-as-mainframe idea falls apart because you need massive amounts of software infrastructure to treat a cluster like a mainframe. you have to use Paxos or Raft for serializing operations, you have to shard data and handle failures, etc. etc.
but it's definitely getting closer, thanks to lots of distributed systems engineering.
I wouldn't really agree with this since those machines don't share address spaces or directly attached busses. Better to say it's a warehouse-scale "service" provided by many machines which are aggregated in various ways.
I wonder though.. could you emulate a 20k-core VM with 100 terabytes of RAM on a DC?
Ethernet is fast, you might be able to get in range of DRAM access with an RDMA setup. cache coherency would require some kind of crazy locking, but maybe you could do it with FPGAs attached to the RDMA controllers that implement something like Raft?
it'd be kind of pointless and crash the second any machine in the cluster dies, but kind of a cool idea.
it'd be fun to see what Task Manager would make of it if you could get it to last long enough to boot Windows.
I have fantasized about doing this as a startup, basically doing cache coherency protocols at the page table level with RDMA. There's some academic systems that do something like it but without the hypervisor part.
My joke fantasy startup is a cloud provider called one.computer where you just have a slider for the number of cores on your single instance, and it gives you a standard linux system that appears to have 10k cores. Most multithreaded software would absolutely trash the cache-coherency protocols and have poor performance, but it might be useful to easily turn embarrassingly parallel threaded map-reduces into multi-machine ones.
You absolutely can, but the speed of light is still going to be a limitting factor for RTT latencies, acquiring and releasing locks, obtaining data from memory, etc.
It's relatively easy to have it work slowly (reducing clocks to have a period higher than max latency), but becomes very hard to do at higher freqs.
Beowulf clusters can get you there to some extent, although you can always do better with specialized hardware and software (by then you're building a supercomputer...)
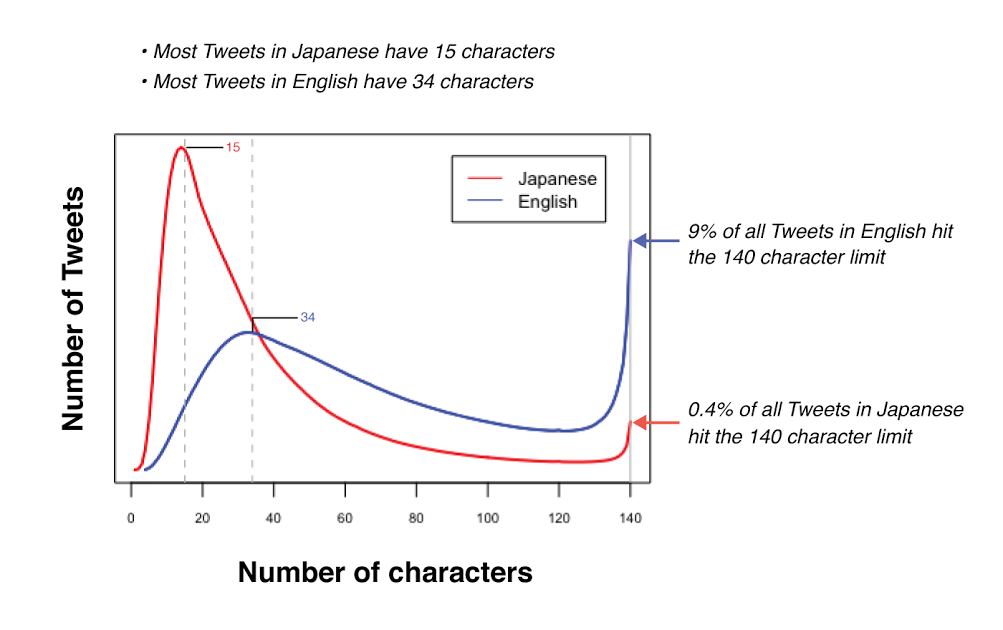
I specifically assumed a max tweet size based on the maximum number of UTF-8 bytes a tweet can contain (560), with a link to an analysis of that, and discussion of how you could optimize for the common case of tweets that contain way fewer UTF-8 bytes than that. Everything in my post assumes unicode.
URLs are shortened and the shortened size counts against the tweet size. The URL shortener could be a totally separate service that the core service never interacts with at all. Though I think in real twitter URLs may be partially expanded before tweets are sent to clients, so if you wanted to maintain that then the core service would need to interact with the URL shortener.
Thanks for clarifying. I missed the max vs. average analysis because I was focused on the text. Still, as noted in the Rust code comment, the sample implementation doesn’t handle longer tweets.
If it counted UTF-16 code units that would be dumb. It doesn't. The cutoff was deliberately set to keep the 140 character limit for CJK but increase it to 280 for the rest. And they did that based on observational data.
As the author, this sounds good to me! I'll probably even change the actual title to match. I originally was going to make it a question mark and the only reason I didn't is https://en.wikipedia.org/wiki/Betteridge%27s_law_of_headline... when I think the answer is probably "could probably be somewhat done" rather than "no".
Well this may be the first time that's ever happened :)
Betteridge antiexamples are always welcome. I once tried to joke that Mr. Betteridge had "retired" and promptly got corrected about his employment status (https://news.ycombinator.com/item?id=10393754).
Oooh nice! Your Kyria posts are actually where I first learned about how awesome and cheap SendCutSend is, and got some of the inspiration for the magnets.
I actually ordered a plain steel plate first, but I realized that given that I needed them in a different position to travel compactly than the wide position I like for typing, I wanted them to snap in consistent positions so it wasn't finicky to line up exactly how I liked them.
{kind=link}