Related to your last question, I was always puzzled by the following: when is a program an implementation of an (abstract) algorithm?
For example, can a program decide, given a sorting function implemented in language X, and an algorithm Y, whether or not the sorting function is an implementation of algorithm Y?
Part of the question is how to represent algorithms (is "formal" pseudo-code the best way?)
Also, can you decide whether or not two functions written in different programming languages are implementations of the same algorithm?
> For example, can a program decide, given a sorting function implemented in language X, and an algorithm Y, whether or not the sorting function is an implementation of algorithm Y?
Assuming the usual things (e.g. that an algorithm Y can be specified in some useful, say, very high level language) then this problem is Halting-hard (e.g. at least as hard as the halting problem), because it would be showing the equivalence of two programs. A similar case applies to your latter question.
I'm not sure there's a good way of specifying abstract algorithms without running into this problem, but I'd be interested in defining a bit further what you might be thinking about.
I should have been clearer, but I'm mostly interested in structure (traversal) algorithms, most of which could be coded in a language with bounded loops.
An easier question is the one of determining the complexity of an algorithm. I think there's a ton of work in this area, for example in techniques that use typing systems (types may for example specify how many times a parameter is used, thus allowing the program to infer the complexity).
(easier because the equivalence relation of "implementing the same algorithm" is strictly finer than "having the same complexity")
i have been writing a gameboy emulator for the last year (with short bursts of work where i implement some module), and it's been very challanging and fun, i recommend everyone to try it.
it has a very simple 8-bit (risc) architecture, but obviously tailored for games (for example, it has a dedicated sprite memory sector). i recommend people to try it out because it is has fun quirks compared with "regular" architectures, like arm and x86, for example in the way it handles cartridges, or in that some cartridges actually had non-trivial logic inside them and weren't just a rom.
it always amazes me how active gameboy research and development is still today, for example there's a very recent gameboy emulator / research project done in rust https://github.com/Gekkio/mooneye-gb
there are even test roms with which you can test your emulator to see if it implements all opcodes, interrupts and whatnot correctly (where correctly not only means "with respect to the effects" but also with respect to how many cycles everything should take). example of these test roms: http://gbdev.gg8.se/files/roms/blargg-gb-tests/
The 8080/Z80 variant that is used in the Game Boy is not a RISC architecture - it is a processor architecture from a time long before the term "RISC" was even used the first time.
While the terms RISC/CISC are defined somewhat vaguely, there are still some common properties of architectures that are considered RISC:
- Load-store architecture:
Counterexample: ADD A,(HL)
- Lots of general purpose registers:
The 8080 has rather few:
B,C,D,E,H,L,A as 8 bit registers and BC,DE,HL,SP as 16 bit registers
- Very orthogonal instruction set:
Counterexample: AND has always destination A
- Often pipelined architecture (though this is not very specific to RISC)
- Instructions typically aim to be run in one cycle (when pipelined)
Counterexample: Look at the instruction timing tables
The instruction encoding is quite regular -- it follows the 2-3-3 pattern that came from the 8008 (if not earlier), and thus looks much better in octal than hex:
> The instruction encoding is quite regular -- it follows the 2-3-3 pattern that came from the 8008 (if not earlier)
While it is true (and I am aware of it) that the Z80 instructions follow the 2-3-3 pattern, it is nevertheless not that regular. Best look at the "purest example" for this that is referred in the literature all the time and acted as a model for the criterion that in RISC the instruction format is very regular: the instruction format(s) used by MIPS. Here there only exist 3 different types of instruction (R-type, I-type and J-type) and all have a very regular pattern. One can find very suggestive pictures at
I did something similar with NES; built an emulator, and come back to it every couple of years. It's had 2 CPU cores (2nd added recognition of idle loops, and runs instructions in chunks instead of 1 at a time), 3 PPU implementations (each iteration emulated at a higher level, adding caching and hardware compositing), and 2 implementations of the ROM subsystem (adding caching and multiple memory mappers the second time around).
There are similar testing ROMs for NES emulators, too. My emulator tends to pass the CPU tests and fail some of the PPU ones; guess I need to write a 4th implementation of that chip!
Cartiridges being more than just ROM has been a staple of Nintendo designs all the way back to the NES.
A common trick was to have a logic chip sit between the ROM and the console, doing bank switching. This allowed a game to consist of much more data than could be fitting directly on the data lines provided.
Some games, particularly those sold in Japan, had improved sound chips for example.
And by the time we reach the SNES, Nintendo used this to even introduce rudimentary 3D acceleration in the form of the SuperFX chip.
For NES, another cool approach takes advantage of the fact that the cartridge is natively split between CPU memory and PPU memory. This means that it's possible to make a cartridge with RAM instead of ROM for the tile pattern data ("CHR" in NES jargon), thus enabling things like pseudo-framebuffer operation, compressed/generated graphics, and animations that work by modifying the tile data or depend on its organization in memory [1]. Strictly speaking, there's no reason that RAM and ROM couldn't be combined in this address space with a mapper, but I haven't heard of any cartridges that do so.
i've been using sway[0] as my wm for some time now (it's a sort of port of i3 to wayland) and it's incredible that you can actually tell that it is much faster than wms running on X.
This is awesome, great write-up, thank you very much.
You briefly mention that crypto-currencies are used for money laundering. Do you think that's what's driving btc price to insane levels? Or is it just good old euphoria?
It might also be that the central banks are printing money like hell, and people look for places where their value stays better.
For example ECB (european central bank) is issuing 60 billion euros new money each month, and buying bonds with it. That is half of the bitcoin market cap.
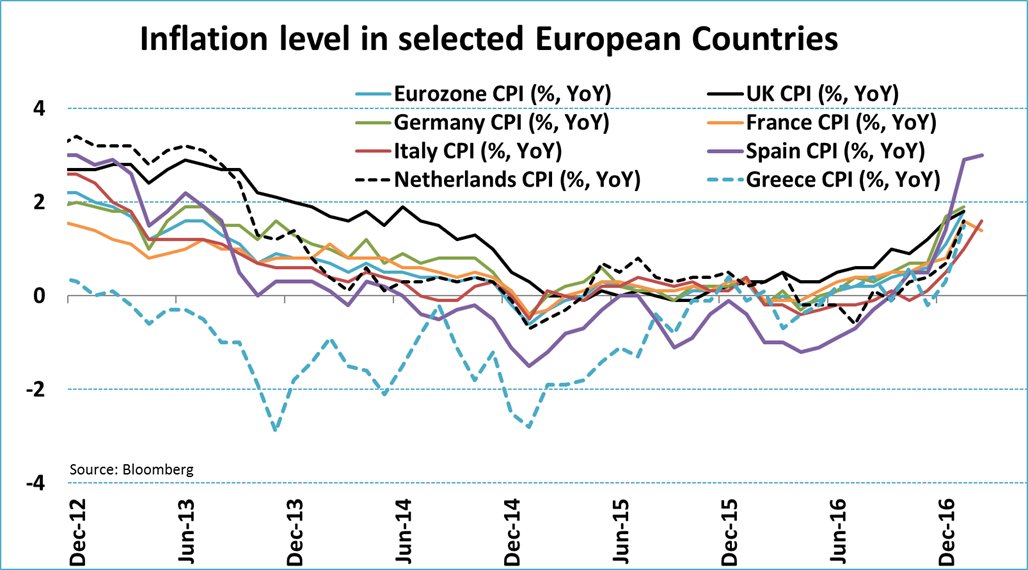
CPI is fairly useless anyway. It ignores where the huge money displacements are actually going: hint, not bread and circuses. The money the ECB is displacing is institutional investors money and causes inflation in things like housing, stock markets, VC funds, and yeah, probably cryptocurrency.
Rent is included in the CPI, and it usually co-moves with housing prices .. and yet .. it means no difference: https://www.ecb.europa.eu/pub/pdf/other/mb201008_focus06.en.... (it's much more drastic in the US CPI - probably because more people own their homes in the EU and gentrification and other effects are a lot slower too? who knows..)
{kind=link}